
Java 基础概念·Java List
Java List
本文为个人学习摘要笔记。
原文地址:List 中的 ArrayList 和 LinkedList 源码分析
List 是单列集合 Collection 下的一个实现类,List 的实现接口又有几个,一个是 ArrayList,还有一个是 LinkedList,还有 Vector,这次研究下这三个类的源码。
ArrayList
ArrayList 是我们在开发中最常用的数据存储容器,它的底层是通过数组来实现的。我们在集合里面可以存储任何类型的数据,而且他是一个顺序容器,存放的数据顺序就是和我们放入的顺序是一致的,而且他还允许我们放入 null 元素,我们可以画个图理解一下。
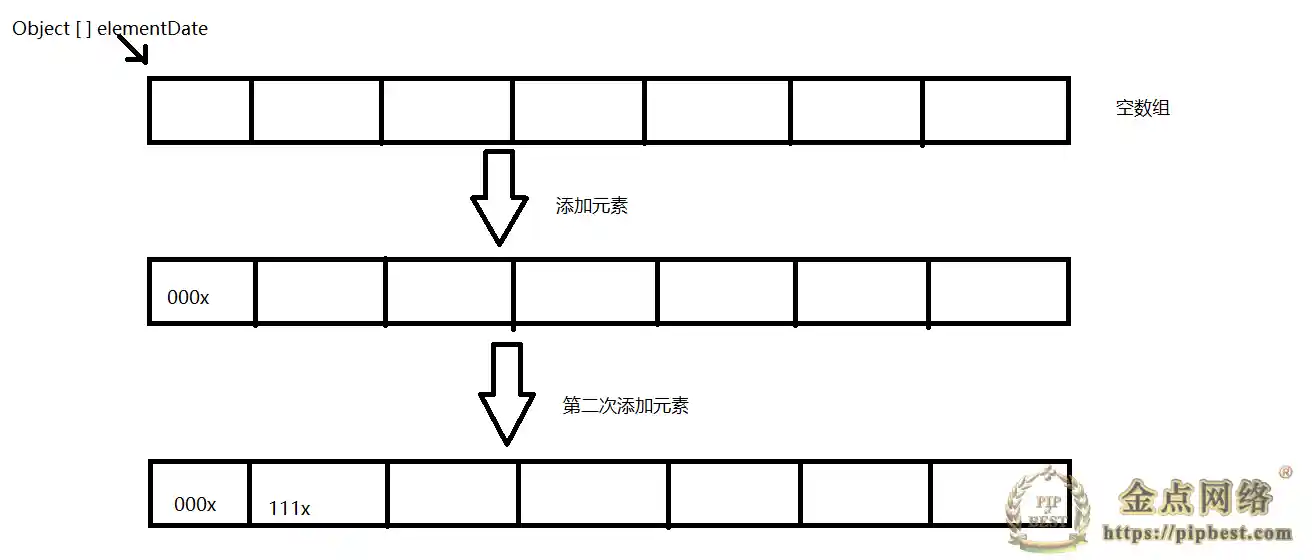
上图数组里面存放的元素的引用,再分析下源码。
源码分析
DEFAULT_CAPACITY 是默认的初始容量,容量是 10,EMPTY_ELEMENTDATA 这代表的是一个空的初始化数组(自定义容量为 0)。 DEFAULTCAPACITY_EMPTY_ELEMENTDATA 区别上边,他是未自定义容量的空数组。
EMPTY_ELEMENTDATA 与 DEFAULTCAPACITY_EMPTY_ELEMENTDATA 区别在哪?通过他的构造函数了解下。
构造
无参构造器构造一个初始容量为 10 的数组,但是构造函数只是给 elementDate 赋值了一个空数组,其实就是在我们添加元素的时候,容量自动扩充为 10。
总结:如果是使用无参构造时,是把 DEFAULTCAPACITY_EMPTY_ELEMENTDATA 给了 elementDate ,当 initialCapacity 为 0 的时候,就把 EMPTY_ELEMENTDATA 赋值给了 elementDate,如果 initialCapacity 大于 0,就会初始化一个 initialCapacity 长度的数组给 elementDate。
迭代器
使用过 ArrayList 的人一般都知道,在执行 for 循环的时候一般情况是不会去执行 remove 的操作的,因为 remove 的操作会改变这个集合的大小, 所以会有可能出现数组角标越界异常。
具体详情可以参考:18 Java fail fast
这里再次分析下源码:
在这个方法内部 next 是最主要的一个方法,他首先去判断了 expectedModCount 和 modCount 是否一样,然后去看 cursor,是不是超过集合的大小和数组的长度,然后去把 cursor 的值给 lastRet,返回的是下标 lastRet 的元素,最后 cursor 加 1,这样就是说每调用一次 next 方法,cursor 和 lastRet 都会加 1。
当我们在调用 remove 方法的时候,他会去判断 lastRet 是否小于 0,然后去判断 expectedModCount 和 modCount 是否一样,然后他去调用 ArrayList.remove() 方法去删除下标是 lastRet 的元素,然后把 lastRet 赋值给 cursor,然后初始化 lastRet = -1,最后把 modCount 重新赋值给 expectedModCount。
LinkedList
LinkedList 的底层是一个双向链表的结构,它可以进行高效的插入和移除的操作。

LinkedList 是由很多个这样的节点组成的:
- prev 是存储的上一个节点的引用
- element 是存储的具体的内容
- next 是存储的下一个节点的引用
整体结构:

图解中可以看出 LinkedList 有好多的 Node,并且还有 first 和 last 这两个变量保存头部和尾部节点的信息。
需要注意:LinkedList 不是一个循环的双向链表,因为他前后都是 null。
源码分析
变量
构造方法
Node 节点
addAll
addFist
将 e 元素添加到链表并且设置其为头节点 Fist:
addLast
将元素添加到链表,并且设置为尾部的节点 next:
需要注意:ArrayList 和 LinkedList 都是线程不安全的,因为,他内部的方法都没有进行方法同步,或者说是加锁。
Vector
Vector 并不常用,他是一个可实现自动增长的数组,同时也是一个线程安全的数组。
synchronized 关键字表面的意思是:当有两个并发线程同时访问一个对象代码块的时候,在同一个时刻,只能有一个线程得到执行,而另外的一个线程受到阻塞,必须等待当前线程的代码执行完这个代码块之后才能执行该代码。
也就是说在执行 synchronized 代码块的时候会锁定当前的对象,只有执行完改代码块之后才能释放锁,下一个线程开始锁定对象执行。
总结
List 实现类:
- ArrayList–>数组结构–>线程不安全,效率高–>查询快,增删慢–>容量不够扩容,当前容量长度*1.5+1;默认长度为 10,第一次扩充后的长度为 16,第二次扩充后的长度为 25,第三次扩从后的长度为 38.5,不取用四舍五入,为 38; 但是要注意,JDk1.7 是 1.5+1;而 JDK8 是 1.5,所以视情况而定
- LinkedList–>双向链表结构–>线程不安全,效率高–>查询慢,增删快–>链表直接在头部尾部新增都可以,所以没有倍数;
- Vector–>数组结构–>线程安全,效率低–>查询快,增删慢–>扩容长度是:当前容量长度*2;
金点网络-全网资源,一网打尽 » Java 基础概念·Java List
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。
- 是否提供免费更新服务?
- 持续更新,永久免费
- 是否经过安全检测?
- 安全无毒,放心食用



