
JavaScript·JavaScript 正则技巧
JS 正则技巧
何为正则?一句话总结:正则是匹配模式,要么匹配字符,要么匹配位置。
字符匹配
模糊匹配
正则除了精确匹配,还能实现模糊匹配,模糊匹配又分为横向模糊和纵向模糊。
横向模糊匹配
横向模糊指的是,一个正则可匹配的字符串的长度不是固定的。其实现方式是使用量词,譬如 {m, n},表示连续出现最少 m 次,最多 n 次。
正则 g 修饰符表示全局匹配,强调“所有”而不是“第一个”。
纵向模糊匹配
纵向模糊指的是,一个正则匹配的字符串,具体到某一位字符时,它可以不是某个确定的字符。其实现方式是使用字符组,譬如 [abc],表示该字符是可以字符 "a"、"b"、"c" 中的任何一个。
字符组
虽然称为字符组,但匹配的其实只是一个字符。譬如字符组 [abc] 只是匹配一个字符。字符组有范围表示法、排除法和简写形式。
范围表示法
字符组 [0-9a-zA-Z] 表示数字、大小写字母中任意一个字符。由于连字符"-"有特殊含义,所以要匹配 "a"、"-"、"c" 中的任何一个字符,可以写成如下形式:[-az]、[az-]、[a\-z],连字符要么开头,要么结尾,要么转义。
排除字符组
排除字符组(反义字符组) 表示是一个除 "a"、"b"、"c"之外的任意一个字 符。字符组的第一位放 ^(脱字符),表示求反。^ 可以配合范围表示法使用,如 。
简写形式
正则简写形式如下:
| 字符组 | 含义 |
|---|---|
| \d | [0-9],表示数字 |
| \D | [^0-9],表示非数字 |
| \w | [0-9a-zA-Z_],表示数字、大小写字符和下划线 |
| \W | [^0-9a-za-z_],表示非单词字符 |
| \s | [ \t\v\n\r\f],表示空白符 |
| \S | [^ \t\v\n\r\f],表示非空白符 |
| . | 通配符 |
需要注意:[ \t\v\n\r\f] 分别表示空白符、水平制表符、垂直制表符、换行符、回车符、换页符。
通配符 . 可以表示几乎任意字符。换行符、回车符、行分隔符和段分隔符除外。如果想要匹配任意字符,可以使用组合写法:[\d\D]、[\w\W]、[\s\S] 和 [^] 中任何的一个。
量词
简写形式
| 量词 | 含义 |
|---|---|
| {m, n} | 表示出现 m 到 n 次 |
| {m,} | 至少出现 m 次 |
| {m} | 等价 {m, m},表示出现 m 次 |
| ? | 等价 {0, 1},表示出现或不出现 |
| + | 等价 {1,},表示至少出现 1 次 |
| * | 等价 {0,},表示出现任意次 |
贪婪匹配与惰性匹配
贪婪匹配会尽可能多的匹配,表现如下:
通过在量词后面加 ? 实现惰性匹配,惰性匹配会尽可能少的匹配,表现如下:
多选分支
多选分支可以支持多个子模式任选其一。具体形式如下:(p1|p2|p3),其中 p1、p2 和 p3 是子模式,用 |(管道符)分隔,表示其中任何之一。需要注意:多选分支是从左到右惰性匹配的,前面匹配成功之后后面的模式便不再尝试。可以通过更改子模式的顺序来改变匹配的结果。
实例应用
匹配文件路径
文件路径格式如 盘符:\文件夹\文件夹\文件夹\。匹配符盘:[a-zA-Z]:\\。匹配文件名或文件夹名,不能包含一些特殊字符,需要排除字符组 来表示合法字符,且文件名或文件夹名不能为空,至少有一个字符,需要使用量词 +。文件夹可以出现任意次,最后可能是文件而不是文件夹,不需要带 \\。
匹配 id
量词 . 是通配符,可以匹配双引号,同时是贪婪匹配,所以出错。可以将其改造成惰性匹配:
但以上正则匹配效率低,因为其匹配原理设计”回溯“ 概念,最优解如下:
位置匹配
位置的概念
位置(锚)是相邻字符之间的位置。可以将位置理解成空字符串。在 ES5 中,一共有六个锚:^、$、\b、\B、(?=p)、(?!p)。
^匹配开头,多行匹配则匹配行开头&匹配结尾,多行匹配则匹配行结尾\b匹配单词边界,即\w与\W、^、$之间的位置\B匹配非单词边界- (?=p) 为正向先行断言(positive lookhead),匹配模式 p 前的位置
- (?!p) 为负向先行断言(negative lookhead),匹配非 p 前的位置
实例应用
数字千分位分隔符
千分位分隔符的插入位置为三位一组数字的前面,且不能是开头位置。
密码验证
密码长度 6-12 位,由数字、大小写字母组成,但必须至少包括 2 种字符。首先考虑匹配 6-12 位的数字、大小写字母:
然后需要判断至少包含两种字符,有两种解法。
第一种解法:首先判断是否包含数字,正则可以表示如下:
重点需要理解 (?=.*[0-9])^,该正则表示开头前的位置,同时也表示开头,因为位置可以表示为空字符串。该正则表示在任意多个字符后有数字。依次类推,如果需要同时包含数组和大写字母可以表示为:
最终正则可以表示为:
第二种解法:“至少包含两种字符” 表示不能全为数字、大写字母或小写字母,不能全为数字可以表示如下:
所以最终正则可以表示为:
括号的作用
分组和分支结构
括号提供了分组,用于引用。引用分两种:在 JavaScript 里引用和在正则里引用。分组和分支结构是括号最直接的功能,强调括号内是一个整体,即提供子表达式。
分组引用
使用括号分组,可以进行数据提取和替换操作。以提取数据为例,提取形如 yyyy-mm-dd 日期年月日:
扩展:在 JavaScript 里,exec 和 match 方法作用基本一致,主要有两点区别:
exec是 RegExp 类分方法,而match是 String 类的方法exec只匹配第一个符合的字符串,而match行为跟是否配置 g 修饰符有关,在非全局匹配情况下,两者表现一致
此外,括号分组还可方便进行替换操作,如将 yyyy-mm-dd 替换为 dd-mm-yyyy:
反向引用
除了在 JavaScript 里引用分组,还可以在正则里引用,即反向引用。举个栗子,以匹配日期为例:
如果出现括号嵌套,则以首次出现的左括号顺序为分组顺序。反向引用有三个 Tips:
- Tip1:如果出现类似 \10,则表示第 10 个分组而不是 \1 和 0,如果需要表示后者,需要使用非捕获括号,表示成 (?:\1)0 或 \1(?:0)。
- Tip2:如果引用不存在分组,则只匹配反向引用的字符本身,如 \2 只匹配 2,反斜杠表示转义。
- Tip3:如果分组后面有量词,则以最后一次捕获的数据为分组。
非捕获括号
之前的例子,括号里的分组或捕获数据,以便后续引用,称之为捕获型分组和捕获型分支。如果只想使用括号原始功能,可以使用非捕获型括号 (?:p) 和 (?:p1|p2|p3)。
回溯法原理
回溯法也称试探法,它的基本思想是:从问题的某一种状态(初始状态)出发,搜索从这种状态出发所能达到的所有“状态”,当一条路走到“尽头”的时候(不能再前进),再后退一步或若干步,从另一种可能“状态”出发,继续搜索,直到所有的“路径”(状态)都试探过。这种不断“前进”、不断“回溯”寻找解的方法,就称作“回溯法”。
”回溯法“本质上是深度优先算法。举个栗子,以正则 /ab{1,3}/c 来匹配字符串 ‘abbc’,其匹配流程如下:
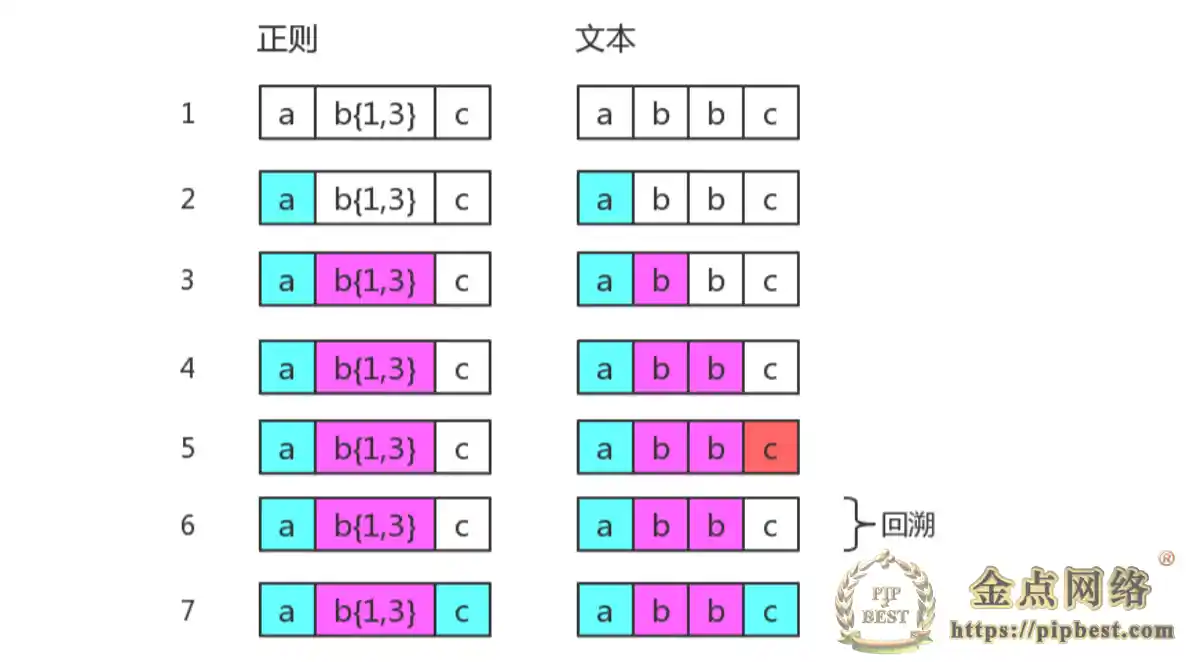
图中第 5 步有红颜色,表示匹配不成功。此时 b{1,3} 已经匹配到了 2 个字符 "b",准备尝试第三个时,结果发现接下来的字符是 "c"。那么就认为 b{1,3} 就已经匹配完毕。然后状态又回到之前的状态,最后再用子表达式 c,去匹配字符 "c"。此时整个表达式匹配成功了。图中第 6 步便称为”回溯“。
以上为贪婪匹配情况下的回溯,在惰性匹配中也存在回溯。再举个惰性匹配的栗子:
尽管是惰性匹配,但为了整体匹配成功,第一个分组还是会多分配一个字符,其整体匹配流程如下:
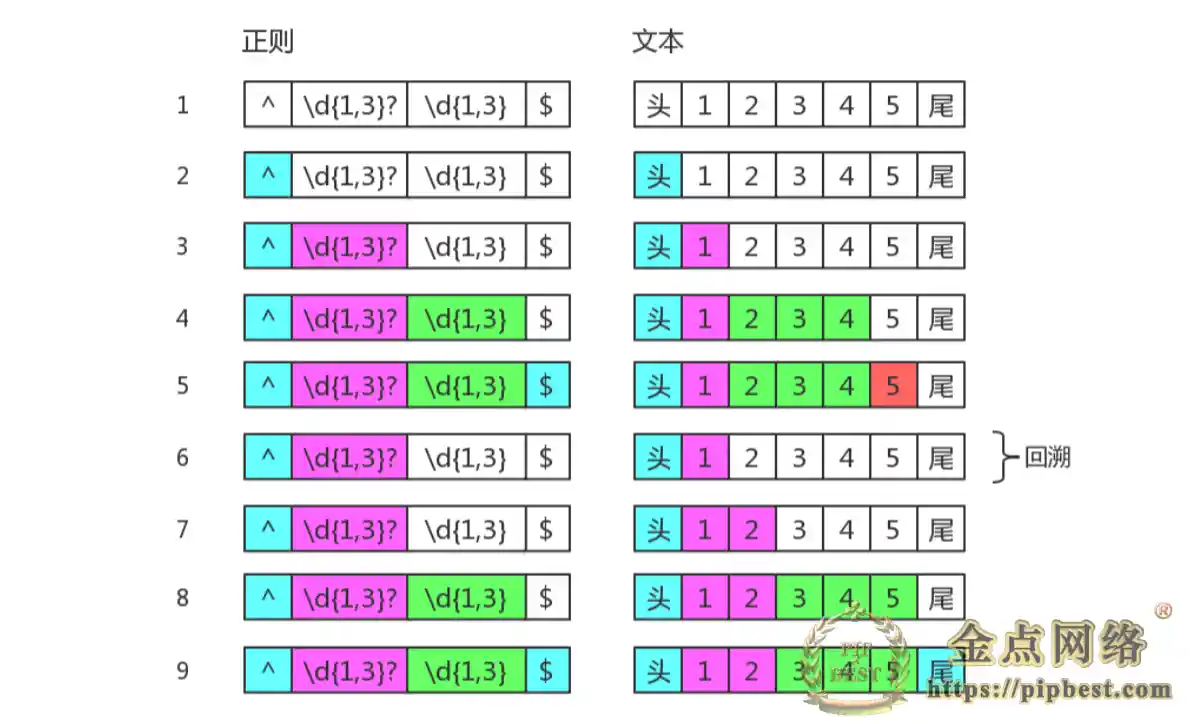
此外,分支结构也可视为一种回溯,在当前分支不满足匹配条件时,会切换到另一条分支。
形象类比一下回溯的几种情况:
- 贪婪量词“试”的策略是:买衣服砍价。价钱太高了,便宜点,不行,再便宜点。
- 惰性量词“试”的策略是:卖东西加价。给少了,再多给点行不,还有点少啊,再给点。
- 分支结构“试”的策略是:货比三家。这家不行,换一家吧,还不行,再换。
正则的拆分
结构和操作符
JavaScript 里正则表达式由字符字面量、字符组、量词、锚、分组、选择分支、反向引用等结构组成。
| 结构 | 说明 |
|---|---|
| 字符字面量 | 匹配一个具体字符,包括转义与非转义 |
| 字符组 | 匹配一个多种可能的字符 |
| 量词 | 匹配连续出现的字符 |
| 锚 | 匹配一个位置 |
| 分组 | 匹配一个括号整体 |
| 选择分支 | 匹配多个子表达式之一 |
其中涉及的操作符有:
| 操作符描述 | 操作符 | 优先级 | |
|---|---|---|---|
| 转义符 | \ | 1 | |
| 括号和方括号 | (…)、(?:…)、(?=…)、(?!…)、[…] | 2 | |
| 量词限定符 | {m}、{m,n}、{m,}、?、*、+ | 3 | |
| 位置和序列 | ^、$、\元字符、一般字符 | 4 | |
| 管道符 | ` | ` | 5 |
元字符
JavaScript 正则里用到的元字符有 ^、$、.、*、+、?、|、\、/、(、)、[、]、{、}、=、!、:、-,当匹配到上面字符本身时,可以一律转义。
正则的构建
构建正则的平衡法则:
- 匹配预期的字符串
- 不匹配非预期的字符串
- 可读性和可维护性
- 效率
这里只谈如何改善匹配效率的几种方式:
- 使用具体型字符组来代替通配符,来消除回溯
- 使用非捕获分组。因为捕获分组需要占用内存来存储捕获分组和分支里的数据
- 独立出确定字符,如
a+可以修改为aa*,后者比前者多确定了字符 a。 - 提取分支公共部分,如
this|that修改为th(:?is|at) - 减少分支数量,如
red|read修改为rea?d
正则编程
在 JavsScript 里,关于正则常用的相关 API 有 6 个,其中字符串实例 4 个,正则实例 2 个:
String#searchString#splitString#matchString#replaceRegExp#testRegExp#exec
字符串实例的 match 和 search 方法,会把字符串转换为正则:
字符串的四个方法,每次匹配时,都是从 0 开始的,即 lastIndex 属性始终不变。而正则实例的两个方法 exec、test,当正则是全局匹配时,每一次匹配完成后,都会修改 lastIndex。
金点网络-全网资源,一网打尽 » JavaScript·JavaScript 正则技巧
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。
- 是否提供免费更新服务?
- 持续更新,永久免费
- 是否经过安全检测?
- 安全无毒,放心食用



